Help
Deriving HTML from PDF
ngPDF allows you to manage the HTML presentation derived from the tagged structure of the original PDF document. It implements Derivation algorithm developed by PDF Association to to derive HTML from Tagged PDF in a predictable manner based on the PDF semantics. In short, this algorithm extracts the content of the PDF document recombines it into HTML using the logical structure of the PDF.
Upload page
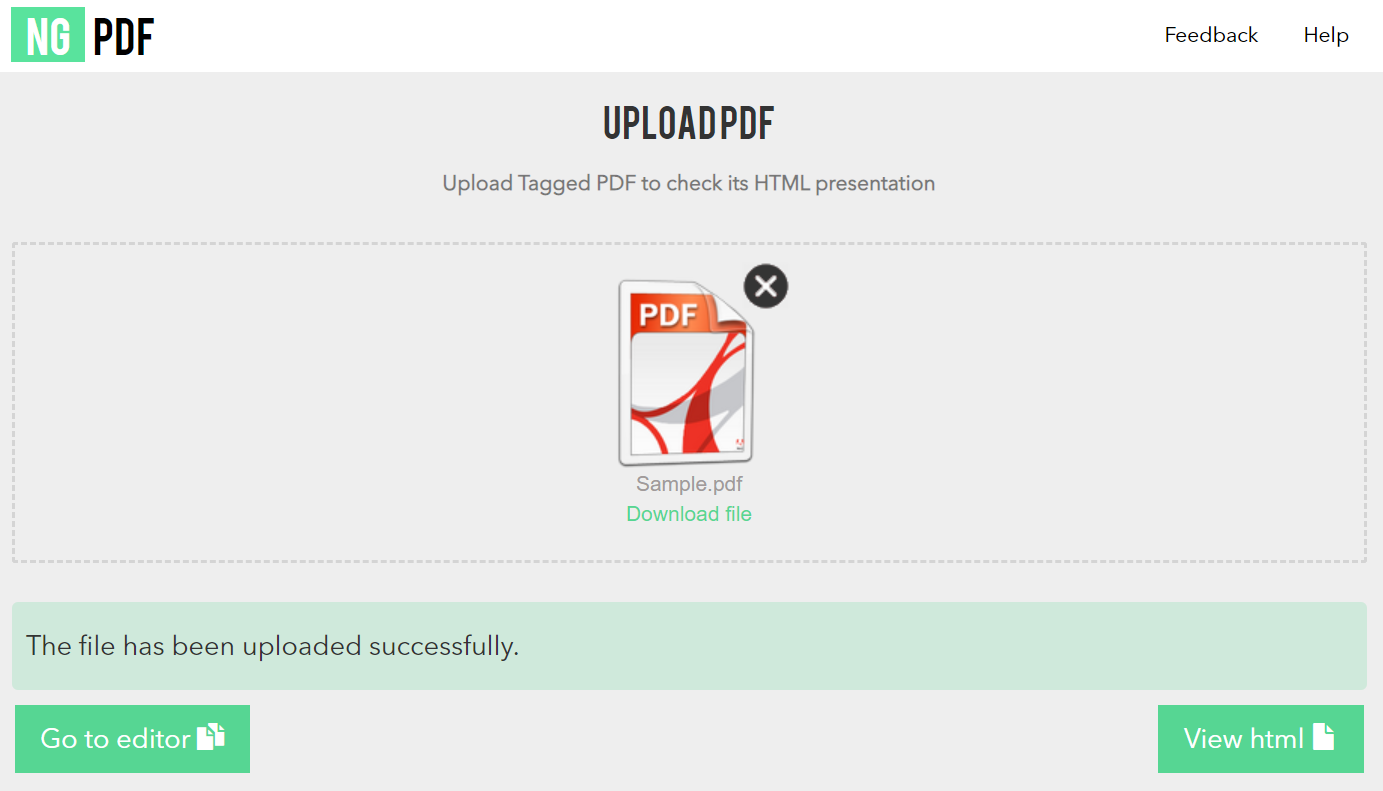
To start working with ngPDF, upload your Tagged PDF document by dropping it to the grayed upload area or just mouse click this area to open the file selection dialog.
PDF file requirements
- The PDF document should be tagged (or marked). In other words it should contain a valid semantic structure as specified in PDF 1.7 or PDF 2.0 Reference, Section 14.8.
- If the PDF document is encrypted, it should have permissions to extract text and images.
- The demo version of the application does not support PDF files bigger than 20Mb.
If the document complies to all these requirement, you will see two buttons appearing below the download area:
- Go to editor button will allow you to inspect the structure tree of the PDF document and adjust the HTML presentation of your PDF
- View html button will open the derived HTML presentation in a new tab.
If you do not have any Tagged PDF documents at hand, you can always play with our sample PDF by clicking Try out quick start sample.
Editor
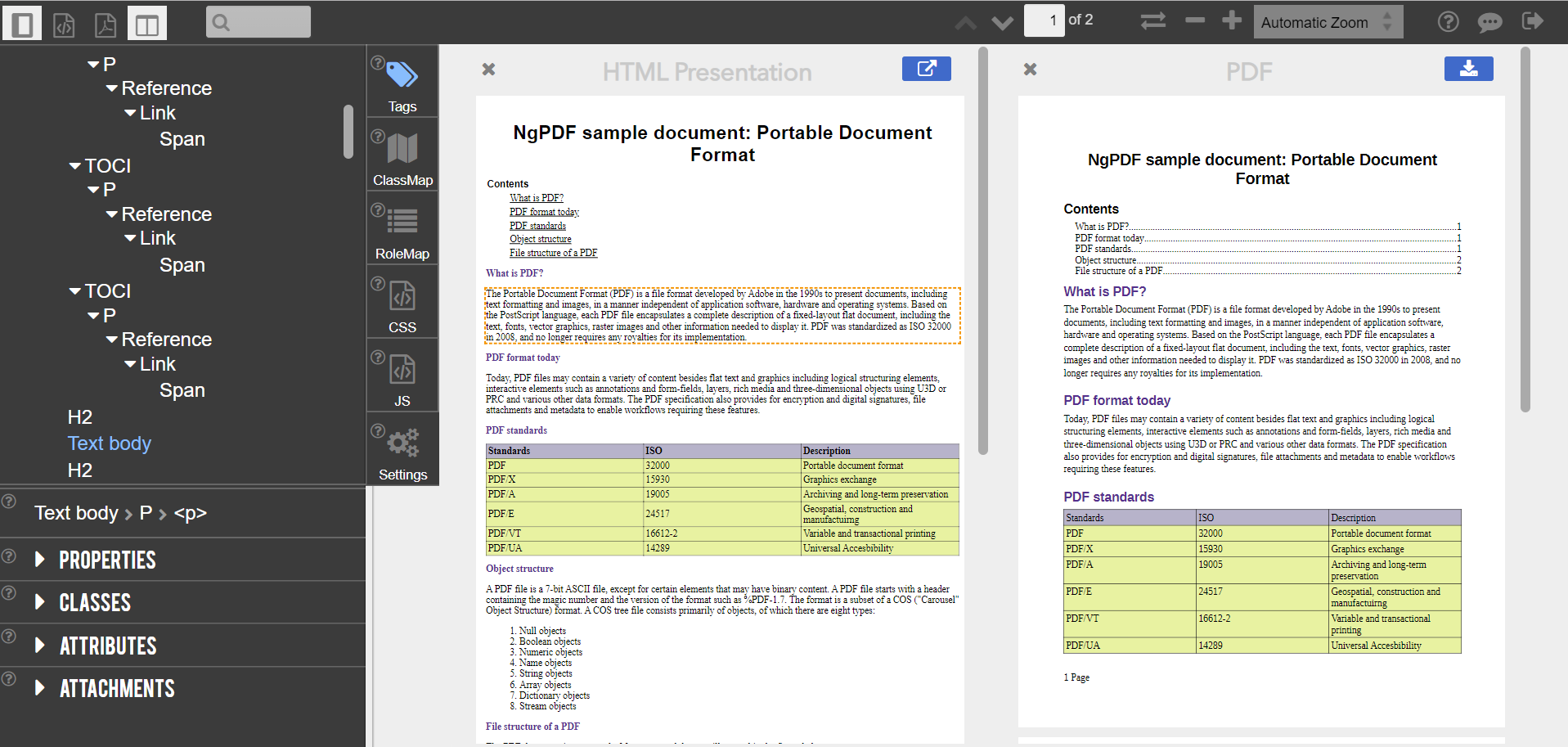
The Editor opens a window split vertically into the following areas:
- on the right you see the original PDF document
- on the left is the HTML presentation derived from the tagged structure of the PDF document.
- in addition, one can enable / disable Tools pane on the left-hand side showing the details of the structure tree
Inspecting structure elements and their properties
The editor allows you to:
- Inspect the Structure tree: clicking to any area in either HTML or PDF presentation navigates you directly to the corresponding element in the Structure tree.
- Inspect and update properties (in PDF syntax these are entries /Lang, /Alt, /ActualText, /E in the structure element dictionary)
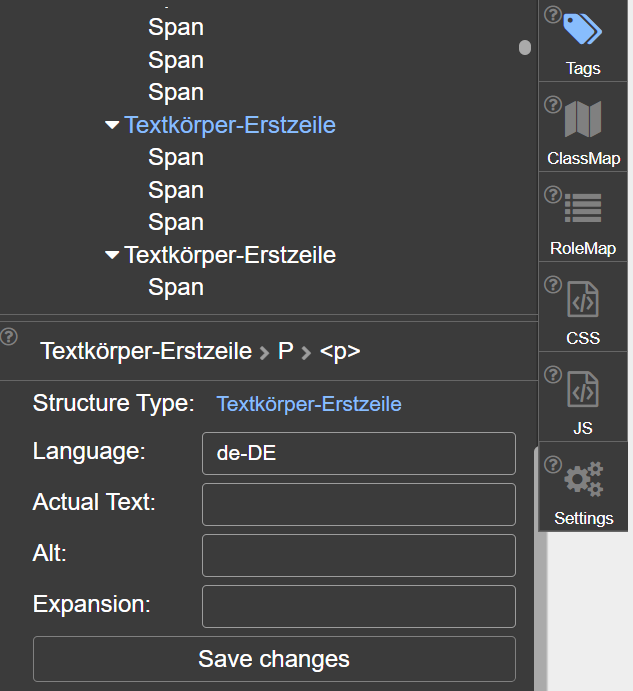
- Inspect and update the class (or classes) of the structure element, all its attributes and the files attached to the structure element (in PDF syntax they are called associated files)
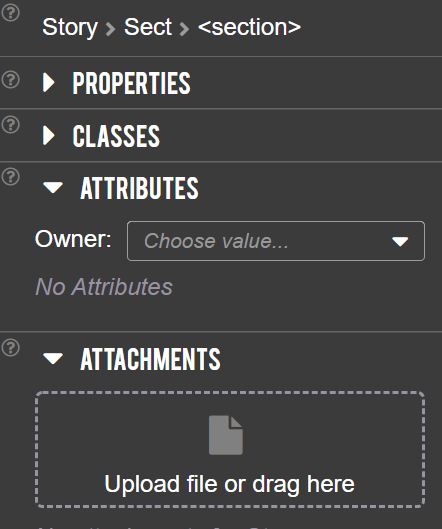
Inspecting global properties of the document
In addition, one can adjust global properties of the document:
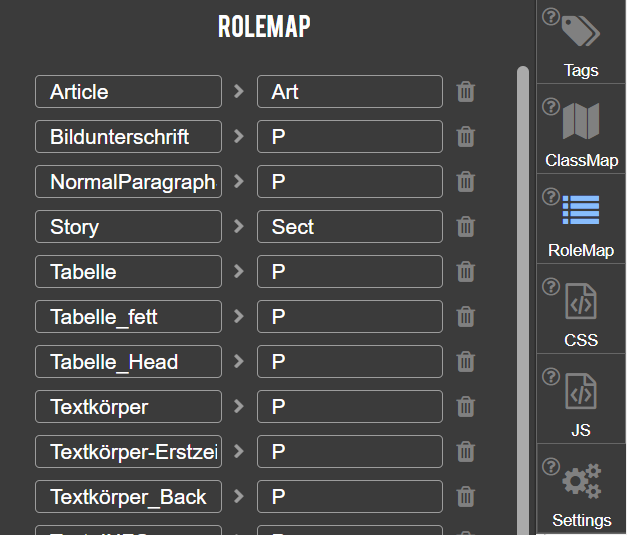
- Inspect and update RoleMap used to map custom tags to the standard PDF 1.7 or PDF 2.0 tags
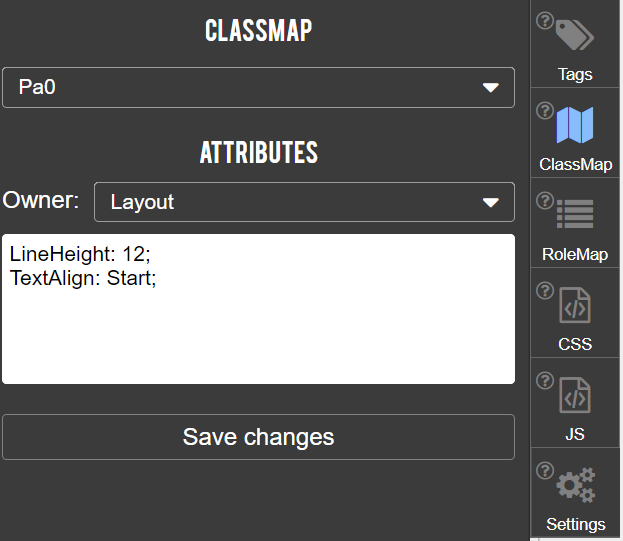
- Inspect and update ClassMap that allows defining groups of element attibutes (see also class property of structure elements)
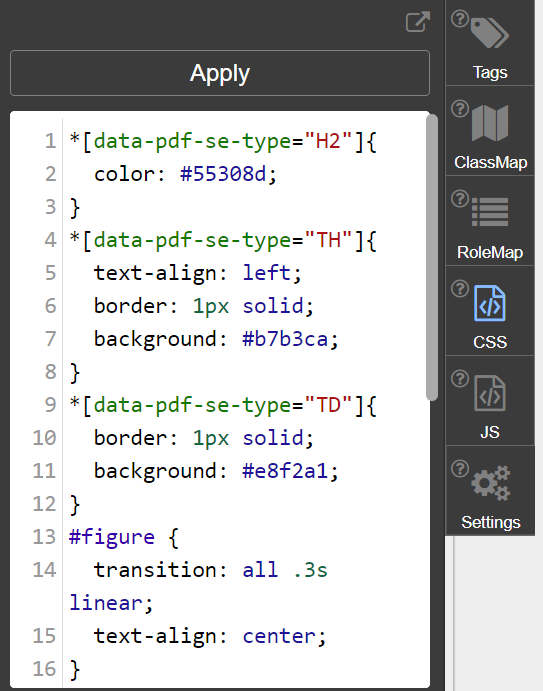
- Manage the document level CSS and JavaScript that will be embedded into the derived HTML presentation. These CSS and JavaScript will be stored inside the PDF document and injected at the beginning of the HTML presentation.
- Adjust the settings of the derivation algorithm. For the moment the only available option enables / disables the use of MathJax in the resulting HTML. Make sure to enable it, if your document contains MathML.
See PDF Reference, Section 14.7 for more details on logical structure of PDF documents and consult the Derivation algorithm for more information how they are used in deriving HTML from PDF.
You can exit the Editor and return to the Upload PDF page by clicking the Exit button in the top right corner. All adjustments including modified attributes and properties, changes in ClassMap and RoleMap structures, custom CSS and JavaScript will be stored in the modified PDF. You can download this modified PDF by clicking Download file link below the file icon.